In this post, we're going to clone the parent process of our container into a child process.
Before that can happen, we'll set up the ground by preparing some inter-process communication channels allowing us to interact with the child process we're going to create.
Inter-process communication (IPC) with sockets
Introduction to IPC
When it comes to inter-process communication (or IPC for short), the Unix domain sockets or "same host socket communication" is the solution.
They differ from the "network socket communication" kind of sockets that are used to perform network operations with remote hosts.
You can find a really nice article about sockets and IPC here
It consists in practice of a file (Unix philosophy: everything is a file) in which we're going to read or write, to transfer information from one process to another.
For our tool, we don't need any fancy IPC, but we want to be able to transfer simple boolean to / from our child process.
Create a socketpair
Creating a pair of sockets will allow us to give one to the child process, and one to the parent process.
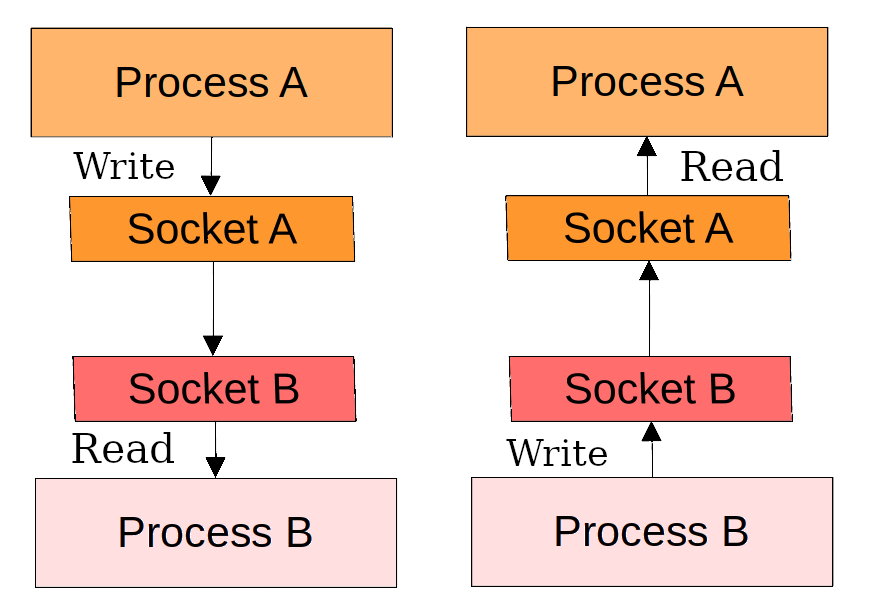
This way we'll be able to transfer raw binary data from one process to the other the same way we write binary data into a file stored in a filesystem.
Let's create a new file src/cli.rs containing everything related to IPC:
use crateErrcode;
use RawFd;
use ;
We create a generate_socketpair function in which we call the socketpair function, which is the standard Unix way of creating socket pairs, but called from Rust.
AddressFamily::Unix: We are creating a Unix domain socket (see all AddressFamily variants for details)SockType::SeqPacket: The socket will use a communication semantic with packets and fixed length datagrams. (see all SockType variants for details)None: The socket will use the default protocol associated with the socket type.SockFlag::SOCK_CLOEXEC: The socket will be automatically closed after any syscall of theexecfamily. (see Linux manual forexecsyscalls)
Rust provides a specific OwnedFd type with plenty of abstraction with it, but as we do pretty low-level stuff with it, it WILL get in the way.
This is why we choose to useRawFdtypes instead (basically ai32), it's much less safe, but will interact correctly with syscalls.
As we use a new Errcode::SocketError variant, let's add it to src/errors.rs now:
Adding the sockets to the container config
When creating the configuration, let's generate our socketpair and add it to the ContainerOpts data so the child process can access to it easily. In the src/config.rs file:
use crategenerate_socketpair;
// ...
use RawFd;
Also let's modify the ContainerOpts::new function so it returns the sockets along with the constructed ContainerOpts struct, the parent container needs to get access to it.
Adding to the container, setting up the cleaning
In our container implementation, let's add a field in the Container struct to be able to access the sockets more easily.
In the file src/container.rs:
use close;
use RawFd;
// ...
As sockets requires some cleaning before exit, let's close them in the clean_exit function.
Creating wrappers for IPC
To ease the use of the sockets, let's create two wrappers to ease the use.
We only want to transfer boolean, so let's create a send_boolean and recv_boolean function in src/ipc.rs:
Here it's just some interacting with the send and recv functions from the nix crate, handling data types conversion, etc...
There's nothing much to say about it, but it's still interesting how we can interact with functions that has a low-level C backend from Rust.
We won't use the wrappers for now, but they'll come handy later.
Patch for this step
The code for this step is available on github litchipi/crabcan branch “step7”.
The raw patch to apply on the previous step can be found here
Cloning a process
In order to regroup everything related to the cloning and management of the child process, let's create a new module child in a file src/child.rs.
First of all, define the modules in src/main.rs:
// ...
We can also create new types of errors to deal with anything going wrong in our child process generation or anything during the preparation inside the container, and add them to src/errors.rs:
Creating a child process
For now, we create a dummy child function simply echoing the arguments it will execute.
We create the function in src/child.rs:
The child process simply outputs something to stdout, and returns 0 as a signal that nothing went wrong.
We also pass it some configuration in which we'll be able to bundle everything we want our child process to acknowledge.
Then we create the function cloning the parent process and calling the child, still in src/child.rs:
use crateErrcode;
use crateContainerOpts;
use Pid;
use clone;
use Signal;
use CloneFlags;
const STACK_SIZE: usize = 1024 * 1024;
Let's split this code to understand it properly:
- We first allocate a raw array (aka buffer) of size
STACK_SIZEthat we define of size1KiB.
This buffer will hold the stack of the child process, note that this is differentfrom the original Cclonefunction (as detailed in the nix::sched::clone documentation) - Secondly we will set the flags we want to activate, a complete list of the flags and their simple description is availablein the nix::sched::CloneFlags documentation, or directly in the linux manual for clone(2).
I'll skip the flags definition for their own separate parts as they deserve some proper explanation. - We then call the
clonesyscall, which is highly unsafe, but we won't particularly care in our tutorial.
This clone redirects to ourchildfunction, with ourconfigstruct as an argument,the temporary stack for the process, the flags we set, along with the instruction tosend the parent process aSIGCHLDsignal when the child exits. - If everything goes well, we get a process ID, or
PIDin short, a number identifying uniquely ourprocess for the Linux kernel.
We return this pid as we will store it in our container struct.
A word about namespaces
If you don't know what Linux namespaces are, I recommend reading the Wikipedia article about it for a quick and somewhat complete introduction.
In one line, a namespace is an isolation provided by the Linux kernel to allow a process in this namespace to have a different version of a resource than the global system.
In practice:
- Network namespace: Have a different network configuration than the whole system
- Host namespace: Have a different hostname than the whole system
- PID: Use any PID numbers inside the namespace, including the
initone (PID = 1) - And many others ...
Check out the linux manual for namespaces for more details about namespaces.
Setting the flags
Back to our child cloning preparation, each flag will create a new namespace for the child process, for the given namespace.
If a flag is not set, usually the namespace the child will be part of will be the one from the parent process.
Here is the complete code:
let mut flags = empty;
flags.insert;
flags.insert;
flags.insert;
flags.insert;
flags.insert;
flags.insert;CLONE_NEWNSwill start the cloned child in a newmountnamespace,initialized with a copy of the namespace from the parent process.
Check the mount-namespaces manual for more informationCLONE_NEWCGROUPwill start the cloned child in a newcgroupnamespace.
Cgroups are explained a bit later in the tutorial as we will use them to restrictthe capabilities our child process have.
Check the cgroup-namespaces manual for more informationCLONE_NEWPIDwill start the cloned child in a newpidnamespace.
This basically mean that our child process will think he will have a PID = X,but in reality in the Linux kernel he will have another one.
Check the pid-namespaces manual for more informationCLONE_NEWIPCwill start the cloned child in a newipcnamespace.
Processes inside this namespace can interact with each other, whereas processes outsidecannot through normalIPCmethods.
Check the ipc-namespaces manual for more informationCLONE_NEWNETwill start the cloned child in a newnetworknamespace.
It will not share the interfaces and network configurations from othernamespaces.
Check the network-namespaces manual for more informationCLONE_NEWUTSwill start the cloned child in a newutsnamespace.
I cannot explain why the name UTS (UTS stands for UNIX Timesharing System),but it will allow the contained process to set its own hostname and NIS domain namein the namespace.
Check the uts-namespaces manual for more information
So while creating our child, we will separate its world from the one of the system, allowing it to modify whatever it wants (at least for the namespaces used) without harming the configuration of our system.
Generate the child from the container
Now that we have our clean generate_child_process function, we can call it in the create function of our container, and store the resulting pid in the struct fields.
In src/container.rs, add:
use crategenerate_child_process;
use Pid;
use waitpid;
Waiting for the child to finish
Now that our container contains everything to generate a new clean child process, we will update the main function to wait for the child to finish.
In src/container.rs:
This way, the container generate the child process using the arguments we give to it, then hold and wait for the child to end before quitting.
The function wait_child is defined in src/container.rs like so:
This function uses the syscall waitpid, from the manual:
The waitpid() system call suspends execution of the calling process until a child specified by pid argument has changed state. By default, waitpid() waits only for terminated children, but this behavior is modifiable via the options argument, as described below.
As we wait for the termination, we will just pass None as options, and return a Errcode::ContainerError error if the syscall didn't finished successfully.
Testing
Maybe since the beginning you were wondering why we need sudo to run our tests, in the first 7 steps that wasn't necessary, but here as we create new namespaces for our child process, theCAP_SYS_ADMIN capacity is needed.
(See the manual for capabilities or this article from LWN).
Here's the output we can get from testing this step:
[2021-11-12T08:52:17Z INFO crabcan] Args { debug: true, command: "/bin/bash", uid: 0, mount_dir: "./mountdir/" }
[2021-11-12T08:52:17Z DEBUG crabcan::container] Linux release: 5.11.0-38-generic
[2021-11-12T08:52:17Z DEBUG crabcan::container] Container sockets: (3, 4)
[2021-11-12T08:52:17Z DEBUG crabcan::container] Creation finished
[2021-11-12T08:52:17Z DEBUG crabcan::container] Container child PID: Some(Pid(134400))
[2021-11-12T08:52:17Z DEBUG crabcan::container] Waiting for child (pid 134400) to finish
[2021-11-12T08:52:17Z INFO crabcan::child] Starting container with command /bin/bash and args ["/bin/bash"]
[2021-11-12T08:52:17Z DEBUG crabcan::container] Finished, cleaning & exit
[2021-11-12T08:52:17Z DEBUG crabcan::container] Cleaning container
[2021-11-12T08:52:17Z DEBUG crabcan::errors] Exit without any error, returning 0Patch for this step
The code for this step is available on github litchipi/crabcan branch “step8”.
The raw patch to apply on the previous step can be found here